Samantha Tirtohusodo
Am 8. und 9. Mai 2023 fand ein spannender Workshop zum Thema Optical Character Recognition (OCR) statt, der vom FID BBI organisiert wurde. Unter der Leitung von Florian Langhanki (Universität Würzburg) erkundeten die Teilnehmer*innen die vielseitige OCR-Software OCR4all und hatten die Möglichkeit, eigene Projekte mitzubringen. Der Workshop war offen für sowohl OCR-Neulinge als auch erfahrene Nutzer*innen und bot einen schrittweisen Einblick in die verschiedenen Funktionen der Software. Vor dem abschließenden Diskussionspanel beantwortete Stefan Büdenbender (Hochschule Darmstadt) in einem interessanten Vortrag die Frage: „Was geschieht mit meinen Forschungsdaten, die ich in OCR4all erstellt habe?“ und gab den Teilnehmenden einen Einblick in die Services des NFDI-Konsortiums text+.
Der Workshop begann mit einer einführenden Präsentation von Anna Lingnau vom FID BBI in Wolfenbüttel und Lena Hinrichsen von OCR-D. Die beiden Expertinnen vermittelten den Teilnehmer*innen ein grundlegendes Verständnis von OCR und erläuterten die Besonderheiten und Herausforderungen dieses faszinierenden Bereichs. Die einführende Präsentation legte den Grundstein für die weiteren Themen, mit denen sich die Teilnehmer*innen in den kommenden zwei Tagen intensiv beschäftigen würden.

Florian Langhanki, Projektmitarbeiter von OCR4all, übernahm dann das Wort und führte die Teilnehmer*innen durch die verschiedenen Schritte der Software. Mit seiner fachkundigen Anleitung der OCR-Technologie konnten selbst Laien schnell erste Erfolge erzielen und die umfangreichen Funktionen der Software nutzen. Zu Beginn des Workshops hatten alle Teilnehmer*innen bereits vorbereitete Bilder ihrer Textdokumente zur Verfügung. Schritt für Schritt wurden sie angeleitet, zunächst eine Region-Segmentierung durchzuführen, um die Textbereiche auf den Bildern zu identifizieren. Anschließend folgte eine Line-Segmentierung, bei der die einzelnen Textzeilen extrahiert wurden. Diese strukturierte Herangehensweise ermöglichte es den Teilnehmer*innen, die OCR4all-Software effektiv einzusetzen und die Grundlage für die Texterkennung zu schaffen. Durch diese praktische Übung konnten sie die verschiedenen Schritte des OCR-Prozesses verstehen und anwenden, um ihre eigenen Textdokumente erfolgreich zu bearbeiten. Ein bemerkenswerter Aspekt des Workshops war die Möglichkeit für die Teilnehmer*innen, die Ground Truth Production eigenständig maschinell zu trainieren. Diese Funktion erlaubte es ihnen, die Genauigkeit und Qualität der OCR-Ergebnisse durch die Anpassung der Trainingsdaten und -parameter zu verbessern. Es war faszinierend zu sehen, wie die Teilnehmer*innen ihre Projekte voranbrachten und ihre eigenen Texterkennungsmodelle erstellten, um spezifische Anforderungen und Herausforderungen zu bewältigen. Diese praktische Erfahrung eröffnete neue Möglichkeiten und verdeutlichte die Flexibilität und Anpassungsfähigkeit von OCR4all.
Diskussion: OCR-Daten als Forschungsdaten
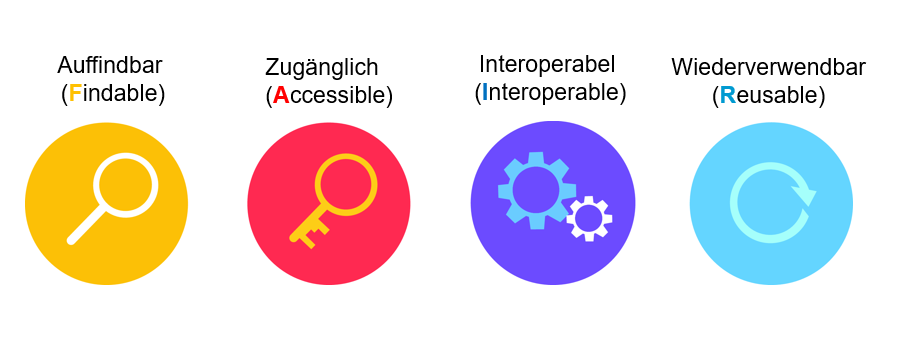
Vor der Abschlussdiskussion bot Stefan Büdenbender von der Hochschule Darmstadt einen interessanten Einblick, wie Forschungsdaten, die mit OCR4all erstellt wurden, verwaltet werden können. Dabei wurden auch die Prinzipien der FAIR (Findable, Accessible, Interoperable, Reusable) und CARE (Collectability, Analyzability, Reusability, Ethics) diskutiert. Büdenbender betonte die Bedeutung der Datenmanagement-Praktiken und gab wertvolle Tipps zur effektiven Organisation und Archivierung von OCR-Projekten, unter Berücksichtigung der FAIR- und CARE-Prinzipien.
Ein zentrales Thema der Diskussion war die Frage der Nachnutzbarkeit und Interoperabilität der erstellten Daten. Büdenbender wies darauf hin, dass eine sorgfältige Dokumentation der OCR-Prozesse und der angewandten Einstellungen für die spätere Interpretation und Verwendung der Daten von entscheidender Bedeutung sei, im Einklang mit den FAIR-Prinzipien.