Das Result Grouping sorgt dafür, dass Sie beim Scrollen durch die Ergebnisliste nicht mehr durch Dubletten gestört werden. Werke mit identischem Titel, Erscheinungsjahr und gleichen Verfasser*innen werden nun gebündelt angezeigt und können bei Bedarf ausgeklappt werden.
Warum gibt es überhaupt Dubletten im FID BBI?
Damit der FID BBI ein möglichst umfassendes Rechercheinstrument darstellt, bündeln wir Daten aus vielen verschiedenen Quellen: Wir filtern Verbundkataloge, Open Access-Repositorien, Nachweisdatenbanken und Verlagsdaten auf Inhalte, die für die drei Fächer relevant sind, und führen sie in unserem Rechercheportal zusammen. Je nach Datenquelle ändern sich die Metadatenformate, die Katalogisierungsregeln und die Komplexität der Einträge. Eine automatische Dublettenkontrolle, die nach exakt gleichen Einträgen oder Identifikationsnummern sucht, „übersieht“ daher einige Dubletten.

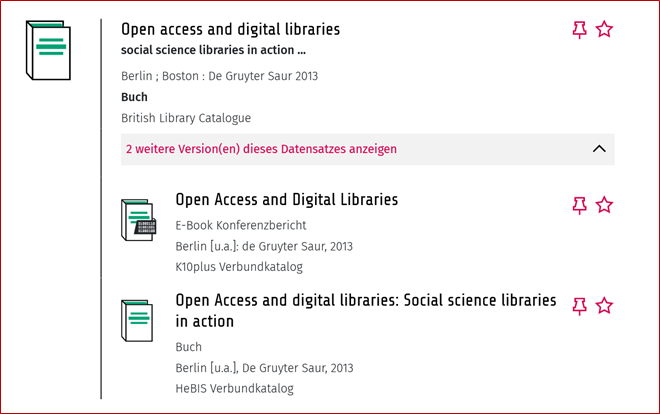
Diese drei Einträge verweisen alle auf den gleichen Titel, werden aber unterschiedlich beschrieben: Beispiel 1 hat einen Haupt- und Untertitel, Beispiel 3 dagegen nur einen Haupttitel, Beispiel 2 verweist auf ein E-Book. Gerade das E-Book soll natürlich nicht aus dem Katalog entfernt werden, da ein digitales Exemplar meist leichter zugänglich ist als die gedruckte Version.
Mithilfe von automatischen Verfahren lassen sich Dubletten (Beispiel 1 und 3) und augenscheinliche Dubletten (Beispiel 2) nicht zuverlässig auseinanderhalten. Eine manuelle Prüfung ist bei mehreren Millionen Einträgen natürlich auch nicht möglich.
Die Lösung: Result Grouping
Die Lösung besteht nun darin, dass wir Titel, bei denen die Wahrscheinlichkeit hoch ist, dass es sich um Dubletten handelt, in unserer Ergebnisliste gruppieren. Die Titel gehen damit nicht verloren, behindern aber auch nicht das Scrollen durch die Ergebnisliste.
Um die Gruppierung zu erreichen, werden sämtliche Datensätze, die in das Portal des FID BBI eingespielt werden, mit einem Matchstring versehen, der aus dem Autor (wenn vorhanden), dem Erscheinungsjahr und dem vollständigen Titel (Haupt- und Untertitel) des Werkes zusammengefügt wird. Der Matchstring für den oben angeführten Titel sieht dann so aus:
:2013:openaccessanddigitallibraries:socialsciencelibrariesinactionlasbibliotecasdeciencassocialesenaccionaccesoabiertoybibliotecasdigitales
Wenn dieser Matchstring bei mehreren Einträgen in der Trefferliste identisch ist, werden die zugehörigen Titel in der Ergebnisliste gebündelt angezeigt. Die Liste kann nach Belieben aus- und eingeklappt werden.
Nachnutzung
Genau wie unser Discovery System Vufind, ist das von der finc-community entwickelte Result Grouping Open Source. Der Code steht anderen Vufind-Anwendern zur Nachnutzung zur Verfügung. Auch im FID adlr.link (FID für Medien- und Kommunikationswissenschaften) kommt das Result Grouping zum Einsatz.
Das Result Grouping kann als unabhängiges Package per Composer eingebunden werden. Voraussetzung ist natürlich, dass in den Metadaten ein Matchstring vorliegt, über den gleichartige Titel identifiziert werden können.